Overview of AWS Glue ETL
AWS Glue is a serverless ETL service that makes it easy to discover, prepare, and combine data for analytics, machine learning, and application development.
AWS has many ETL services like AWS DataPipeline, AWS Redshift but AWS Glue is the recommended service due to its serverless capabilities and many integrations.
AWS Glue Components

AWS Glue Data Catalog
AWS Glue provides both visual and code-based interfaces to make data integration easier. Users can easily find and access data
AWS Glue Studio
Data engineers and ETL (extract, transform, and load) developers can visually create, run, and monitor ETL workflows with a few clicks in AWS Glue Studio
AWS Glue DataBrew
AWS Glue DataBrew is a new visual data preparation tool that makes it easy for data analysts and data scientists to clean and normalize data to prepare it for analytics and machine learning.
AWS Glue Elastic Views
AWS Glue Elastic Views makes it easy to build materialized views that combine and replicate data across multiple data stores without you having to write custom code.
AWS Glue Benefits
- Faster data integration
- Automate your data integration at scale
- Automate your data integration at scale
AWS Glue Use Cases
Build event-driven ETL (extract, transform, and load) pipelines
Run your ETL jobs as new data arrives. For example, you can use an AWS Lambda function to trigger your ETL jobs to run as soon as new data becomes available in Amazon S3. You can also register this new dataset in the AWS Glue Data Catalog as part of your ETL jobs.
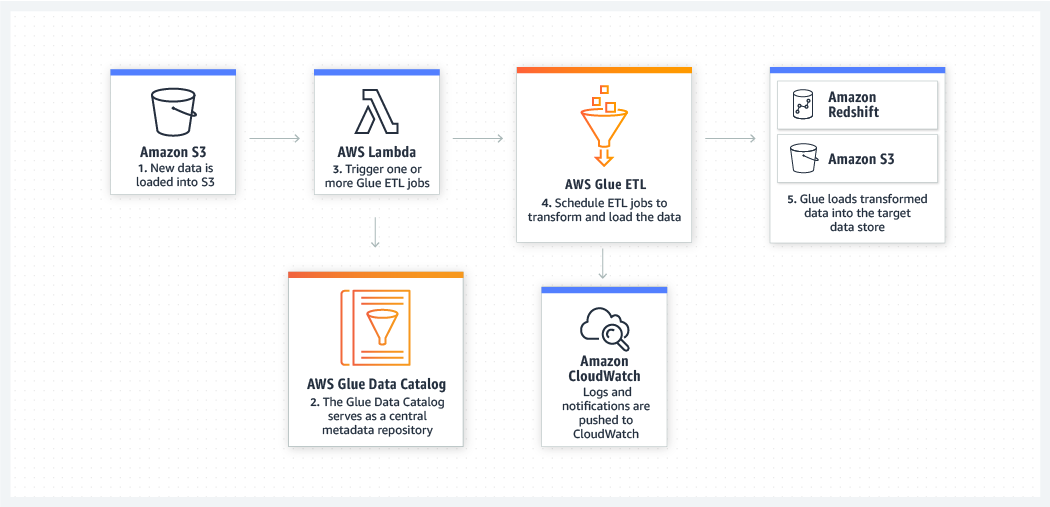
Create a unified catalog to find data across multiple data stores
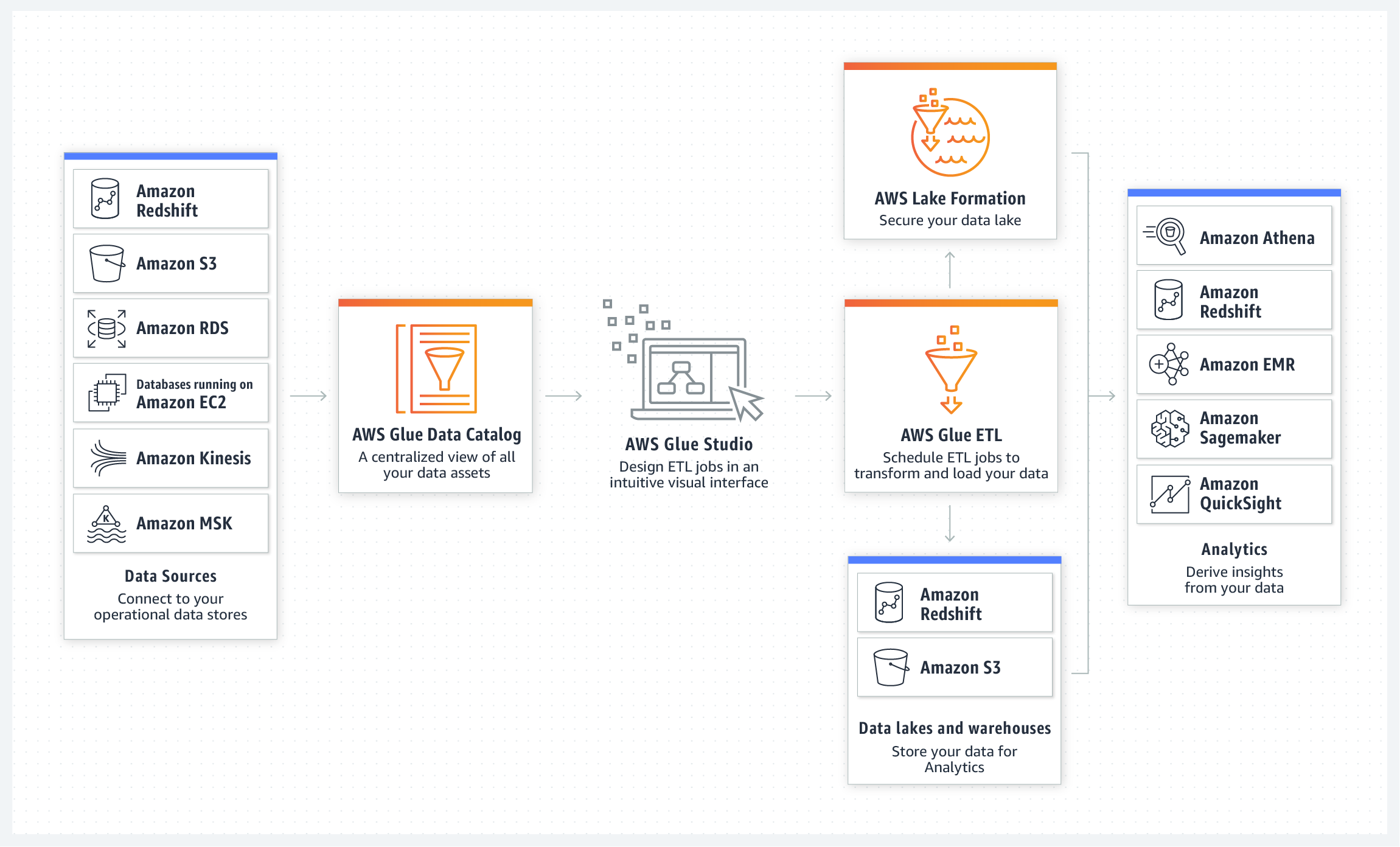
Use the AWS Glue Data Catalog to quickly discover and search across multiple AWS data sets without moving the data. Once the data is cataloged, it is immediately available for search and query using Amazon Athena, Amazon EMR, and Amazon Redshift Spectrum.

Create, run, and monitor ETL jobs without coding
Visually create, run, and monitor AWS Glue ETL jobs using AWS Glue Studio. Compose ETL jobs that move and transform data using a drag-and-drop editor, and AWS Glue automatically generates the code. Use the AWS Glue Studio job run dashboard to monitor ETL execution and ensure that your jobs are operating as intended. Learn more about AWS Glue Studio here.
Explore data with self-service visual data preparation
AWS Glue DataBrew enables you to explore and experiment with data directly from your data lake, data warehouses, and databases, including Amazon S3, Amazon Redshift, AWS Lake Formation, Amazon Aurora, and Amazon RDS.

Build materialized views to combine and replicate data
AWS Glue Elastic Views enables you to use familiar SQL to create materialized views. Use these views to access and combine data from multiple source data stores, and keep that combined data up-to-date and accessible from a target data store.

AWS Glue Pricing
For more information about AWS Glue Pricing , check out post – http://www.cloudinfonow.com/aws-glue-datacatalog-crawler-pricing/
Additional References
More information about AWS Glue ETL can be found in the following links
https://d1.awsstatic.com/events/reinvent/2020/Serverless_data_preparation_with_AWS_Glue_ANT312.pdf
Pingback: AWS Glue Pricing • Cloud InfoNow